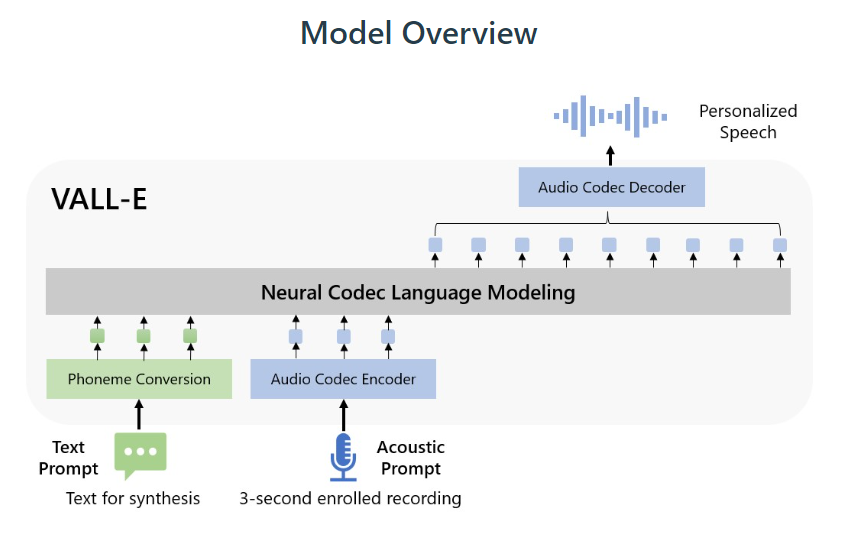
Microsoft has introduced a new language modeling approach for text-to-speech synthesis (TTS) called VALL-E. The approach uses discrete codes derived from an off-the-shelf neural audio codec model, and is trained using 60K hours of English speech, which is hundreds of times larger than existing systems, and can be used to synthesize high-quality personalized speech with only a 3-second enrolled recording of an unseen speaker as an acoustic prompt (project page, paper).
An unofficial Pytorch implementation for VALL-E is available on GitHub.

Leave a Reply