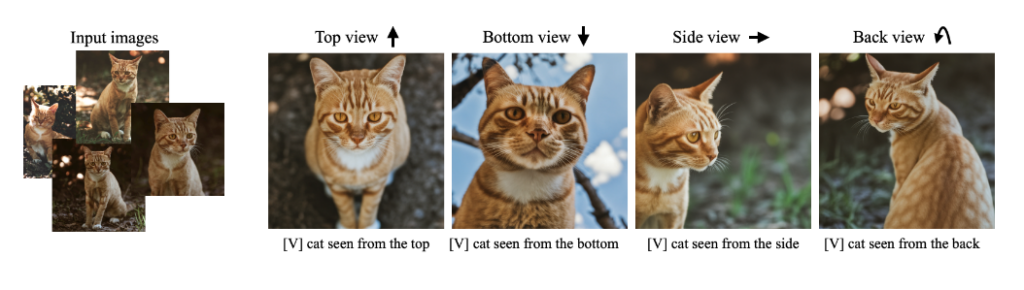
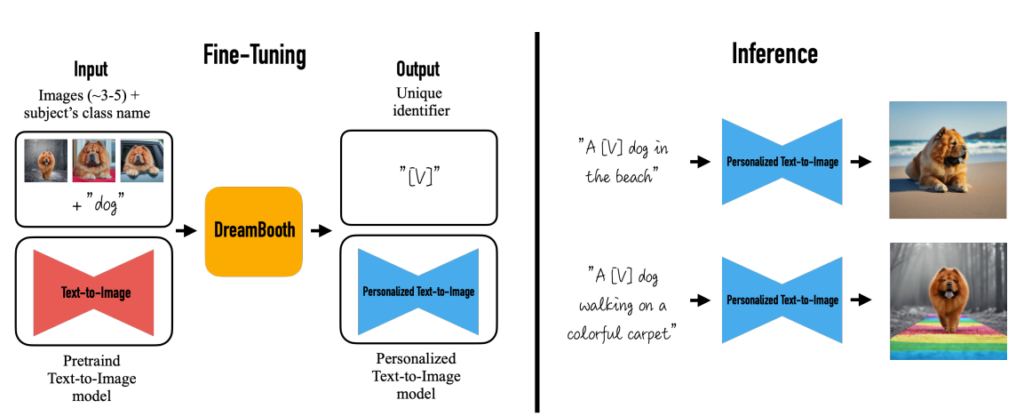
Google presents DreamBooth, a technique to synthesize a subject (defined by 3-5 images) in new contexts defined by text input.
The method is based on Google’s pre-trained text-to-image model Imagen which is not publicly available. However, source code based on Stable Diffusion already exists on GitHub.
Google researchers present Imagic, a method to edit images by text input.
The method is based on Google’s pre-trained image generator Imagen which is not publicly available. However, source code based on Stable Diffusion already exists on GitHub.
A recent publication by University of California, Berkeley [InstructPix2Pix] goes into a similar direction and shows even more impressive results.
The new self-ask prompting technique [Paper] lets the LLM (Large Language Model) formulate sub-questions to a given complex question, answers these simpler questions and finally combines the answers to the answer of the complex question. This technique already improves over chain of thought (CoT) prompting [1][2][3] (but no comparison to self-consistency) . However, with a few lines of source code [GitHub], it is also possible to let the simpler questions be answered by a Google search. In this way also questions relying on facts beyond the training corpus of the LLM can be answered!
Meanwhile people also started to combine LLMs not just with a Google search but also with a Python interpreter [PAL=Program Aided Language Models]. Key tool in this context that allows to build up chains of actions is the Python package LangChain that also already integrates the self-ask technique. See also Dust for reproducing OpenAI’s WebGPT via advanced prompting and Everyprompt for parameterized text prompts within a playground application.
Another interesting technique in this zero-shot context is the Hypothetical Document Embeddings (HyDE) technique as published on 20 Dec 2022 on arXiv. From the abstract of the paper: “HyDE first zero-shot instructs an instruction-following language model (e.g. InstructGPT) to generate a hypothetical document. The document captures relevance patterns but is unreal and may contain false details. Then, an unsupervised contrastively learned encoder~(e.g. Contriever) encodes the document into an embedding vector. This vector identifies a neighborhood in the corpus embedding space, where similar real documents are retrieved based on vector similarity. This second step ground the generated document to the actual corpus, with the encoder’s dense bottleneck filtering out the incorrect details“.
Yet another interesting technique in this context is the Toolformer as published on 09 Feb 2023 on arXiv. From the abstract of the paper: “We introduce Toolformer, a model trained to decide which APIs to call, when to call them, what arguments to pass, and how to best incorporate the results into future token prediction. This is done in a self-supervised way, requiring nothing more than a handful of demonstrations for each API. We incorporate a range of tools, including a calculator, a Q&A system, two different search engines, a translation system, and a calendar. Toolformer achieves substantially improved zero-shot performance across a variety of downstream tasks“
NVIDIA has meanwhile presented with Magic3D a high-resolution text-to-3D content generation model with much higher quality. The paper was released on Nov 18, 2022, on arXiv.
Nobel Prize for physics in 2022 goes to Alain Aspect, John F. Clauser, and Anton Zeilinger for their experiments with entangled photons which proved what Einstein once described as “spooky action at a distance”. Anton Zeilinger got his price for his quantum teleportation experiments that you can verify nowadays on a quantum computer over the cloud. By the way, the spooky action at a distance for entangled photons (i.e. the fact that measuring the polarization of one photon of an entangled pair immediately determines the polarization state of the second photon, no matter of how far the photons are apart, so that there is no possibility that the measurement result can be transferred from the first to the second photon with speed of light) finds a simple explanation in Hugh Everett’s many-worlds interpretation of quantum mechanics that was proposed in 1957, two years after Einstein’s death. Following to this interpretation, with the act of measurement the observer finds himself in a world (of the many worlds) that is consistent with the measurement of the first photon. Thus this observer, who is also a macroscopic quantum object, can only measure this consistent value for the second photon.