On Dec 6, 2023, Google launched its new multimodal model Gemini that will work across Google products like search, ads, and the chatbot Bard. Gemini was trained jointly across text, image, audio, and video and has a 32K context window.
Gemini 1.0 comes in three different sizes:
Gemini Ultra: largest and most capable model to be released at the beginning of 2024
Gemini Pro: best model that is available immediately within Bard in 170 countries (but not yet in the EU and UK)
Gemini Nano: most efficient model for mobile devices with the same availability as Pro; Nano-1 (1. 8B parameters), Nano-2 (3.25B parameters)
Interestingly, Gemini was trained on a large fleet of TPUv4 accelerators across multiple data centers. At such scales, machine failures due to cosmic rays are commonplace and have to be handled (Gemini report, page 4).
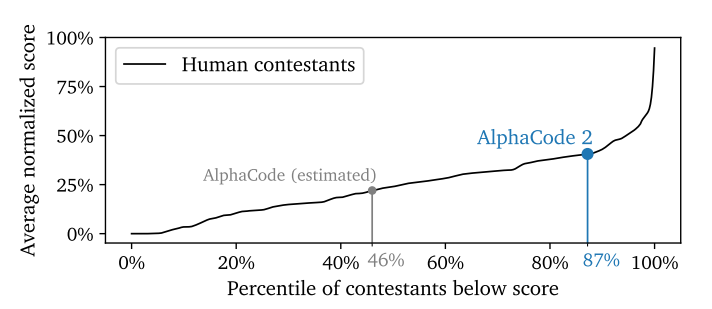
When paired with search and tool-use techniques, Gemini forms the basis for advanced reasoning systems like AlphaCode 2, which excels in competitive programming challenges against human competitors. AlphaCode 2, solely based on Gemini Pro and not yet on Gemini Ultra, shows a substantial improvement over its predecessor by solving 43% of problems on Codeforces, a 1.7x increase. In this way, AlphaCode 2 performs better than 87% of human competitors. However, due to its intensive machine requirements to generate, filter, and score up to a million solutions, AlphaCode 2 is currently not feasible for customer use, although Google is working on this.
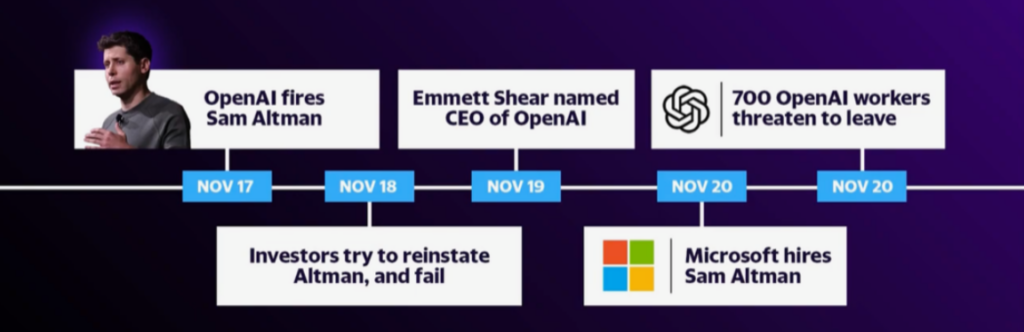
Nov 17, 2023: Sam Altman was fired from OpenAI. Greg Brockman was first removed as chairman of the board, and later he announced to quit. Chief technology officer Mira Murati was appointed interim CEO.
From OpenAI’s announcement: “Mr. Altman’s departure follows a deliberative review process by the board, which concluded that he was not consistently candid in his communications with the board, hindering its ability to exercise its responsibilities. The board no longer has confidence in his ability to continue leading OpenAI. “
Still, no details are known as to why Sam Altman was fired, just more speculations.
Nov 20, 2023: Announcement that Sam Altman and Greg Brockman go to Microsoft and lead a new Microsoft subsidiary. Ilya Sutskever declared his regret for his participation in the board’s actions. Employee Letter to OpenAI’s board signed by more than 700 of the 770 employees (including Ilya Sutskever and one-day CEO Mira Murati) to request the resignation of the whole board and reappointment of Sam Altman as CEO, otherwise they will resign and join the newly announced Microsoft subsidiary. OpenAI’s board approached Anthropic about to merge [1]. Summaries of the latest news: [Matt Wolfe][AI Explained][Bloomberg].
Still, no details are known as to why Sam Altman was fired, just more speculations.
Nov 21, 2023: Summary of the latest status: [Wes Roth].
Instead of taking OpenAI’s merger offer, Anthropic announced a massive update with Claude 2.1 and 200K context window.
Still, no details are known as to why Sam Altman was fired, just more speculations.
Nov 23, 2023: New rumors about Sam Altman’s ouster: Mira Murati told employees on Wednesday that a letter about the AI breakthrough called Q*, precipitated the board’s actions.
Background of why Sam Altman may have been fired: There is much speculation about safety concerning people (like Ilya Sutskever) acting against people trying to accelerate AI commercialization (Sam Altman, Greg Brockmann). As more and more money is poured in, there may be a concern about losing control over OpenAI’s mission to achieve AGI for the benefit of all of humanity. Interesting in this context is a statement [1][2] by Sam Altman at the APEC summit in San Francisco on November 16, 2023 (where US President Biden met Chinese President Xi Jinping) that OpenAI recently made a major breakthrough. In addition, he made a statement [1][2] about the model’s capability within the next year. Does this mean that AGI was achieved within OpenAI? This is important in the context of OpenAI’s structure as a partnership between the original nonprofit and a capped profit arm. The important parts of the document describing the structure are:
First, the for-profit subsidiary is fully controlled by the OpenAI Nonprofit…
Second, … The Nonprofit’s principal beneficiary is humanity, not OpenAI investors.
Fourth, profit allocated to investors and employees, including Microsoft, is capped. All residual value created above and beyond the cap will be returned to the Nonprofit for the benefit of humanity.
Fifth, the board determines when we’ve attained AGI. Again, by AGI we mean a highly autonomous system that outperforms humans at most economically valuable work. Such a system is excluded from IP licenses and other commercial terms with Microsoft, which only apply to pre-AGI technology.
This means that once AGI is achieved (and the board decides when this is the case) investors can no longer benefit from further advancements. Their investment is basically lost.
Another speculation is that the OpenAI’s board member Adam D’Angelo is behind Sam Altman’s ouster. Adam D’Angelo is co-founder and CEO of Quora, which built the chat platform Poe whose recently introduced assistant feature on October 25 is in direct competition with OpenAI’s custom GPTs made public on OpenAI’s DevDay on November 06, 2023. However, this reason becomes less likely as Adam is also part of the new board after rehiring Sam.
Copilot workspace automatically proposes a solution based on its deep understanding of the code base.
Builds a step-by-step plan to implement the changes; if something isn’t quite right, the spec and plan are fully editable.
With the approval of the plan, Copilot automates the implementation of changes across the repository.
Copilot not only synthesizes code but also builds, tests, and validates the success of these changes.
This workspace is designed for collaboration. You can edit any of the suggested changes and if you accidentally introduce an error along the way, Copilot will automatically catch it, repair it, and rerun the code.
Easy to create a pull request with generated summary of the work to merge and deploy fast.
OpenAI rolled out on its DevDay an array of transformative updates and features [blog post, keynote recording]. Here’s a succinct rundown:
Recap: ChatGPT release Nov 30, 2022 with GPT-3.5. GPT-4 release in March 2023. Voice input/output, vision input with GPT-4V, text-to-image with DALL-E 3, ChatGPT Enterprise with enterprise security, higher speed access, and longer context windows. 2M developers, 92% of Fortune 500 companies building products on top of GPT, 100M weekly active users.
New GPT-4 Turbo: OpenAI’s most advanced AI model, 128K context window, knowledge up to April 2023. Reduced pricing: $0.01/1K input tokens (3x cheaper), $0.03/1K output tokens (2x cheaper). Improved function calling (multiple functions in single message, always return valid functions with JSON mode, improved accuracy on returning right function parameters). More deterministic model output via reproducible outputs beta. Access via gpt-4-1106-preview, stable release pending.
GPT-3.5 Turbo Update: Enhanced gpt-3.5-turbo-1106 model with 16K default context. Lower pricing: $0.001/1K input, $0.002/1K output. Fine-tuning available, reduced token prices for fine-tuned usage (input token prices 75% cheaper to $0.003/1K, output token prices 62% cheaper to $0.006/1K). Improved function calling, reproducible outputs feature.
Assistants API: Beta release for creating AI agents in applications. Supports natural language processing, coding, planning, and more. Enables persistent Threads, includes Code Interpreter, Retrieval, Function Calling tools. Playground integration for no-code testing.
Multimodal Capabilities: GPT-4 Turbo supports visual inputs in Chat Completions API via gpt-4-vision-preview. Integration with DALL·E 3 for image generation via Image generation API. Text-to-speech (TTS) model with six voices introduced.
Customizable GPTs in ChatGPT: New feature called GPTs allowing integration of instructions, data, and capabilities. Enables calling developer-defined actions, control over user experience, streamlined plugin to action conversion. Documentation provided for developers.
After weeks of “less exciting” news in the AI space since the release of Llama 2 by Meta on July 18, 2023, there were a bunch of announcements in the last few days by major players in the AI space:
Meta open-sourced Llama 2 together with Microsoft, this time in contrast to Llama 1 free not just for research but also for commercial use.
Free for commercial use for businesses with less than 700 Mio monthly active users
Models with 70B, 13B, and 7B parameters
Llama-2-70B model is currently the strongest open-source LLM (Huggingface leaderboard), comparable to GPT-3.5-0301, noticeably stronger than Falcon, MPT, and Vicuna
Not yet at GPT-3.5 level, mainly because of its weak coding abilities
RLHF fine-tuned
Source code on GitHub, weights available on Azure, AWS, and HuggingFace
Just 4 days after this announcement, on July 22, 2023, StabilityAI released FreeWilly1 and FreeWilly2 which are fine-tuned models based on LLaMA65B and Llama-2-70B. These models took over the leadership on Hugging Face (Huggingface leaderboard). However, both models have no commercial license and are just intended for research.
In a recent study by the University of Montana, GPT-4 demonstrated remarkable performance in the Torrance Tests of Creative Thinking (TTCT, a standard test for measuring creativity), matching the top 1% of human thinkers. The model excelled in fluency and originality. These findings imply that the creative abilities of GPT-4 could potentially surpass those of humans.
For a recent benchmark on advanced reasoning capabilities of large language models take a look at the ARB (Advanced Reasoning Benchmark).
The ChatGPT code interpreter allows users to run code and upload individual data files (in .csv, .xlsx, .json format) for analysis. Multiple files can be uploaded sequentially or within one zip-file. To upload a file, click on the ‘+’ symbol located just to the left of the ‘Send a message’ box or even simpler via drag and drop.
The code interpreter functionality is accessible to ChatGPT Plus users and can be enabled in the settings under ‘Beta features’. Once enabled, this functionality will then appear in the configuration settings of any new chat under the ‘GPT-4’ section, where it also needs to be activated.
Given a prompt, the code interpreter will generate Python code that is then automatically executed in a sandboxed Python environment. If something goes wrong, for instance, if the generated source code requires the installation of a Python package or if the source code is simply incorrect, the code interpreter automatically attempts to fix these errors and tries again. This feature makes working with the code interpreter much more efficient. Before, it was necessary to paste ChatGPT’s proposal into a Jupyter notebook and run it from there. If errors occurred, these had to be fixed either independently or by manually pasting the error text back into ChatGPT so that it could provide a solution. This manual iterative procedure has now been automated with the code interpreter.
Note that the code interpreter executes the source code on OpenAI’s servers, not in the local environment. This leads to restrictions on the size of the uploaded data, as well as a very stringent time limit of 120s for the execution of the code. Given this, it becomes clear what developers truly desire. They seek the integration of this feature into their local development environment, such as VSCode, or within a cloud service, such as AWS, GCP, or Azure, without any restrictions on data size or execution times. This then leans more towards the direction of projects like AutoGPT or GPT Engineer. It’s likely only a matter of days, weeks, or months before such functionality becomes widely available. It’s also probable that complete access to your code repository will be enabled, first through a vector database solution and after some time maybe by including the entire repository within prompts, which are currently increasing dramatically in size (as exemplified in LongNet; since this requires retraining of the LLM such solutions cannot be expected to become available before GPT-4.5 or GPT-5).
For testing, try e.g. the following prompts:
What is the current time?
Plot the graphs of sin(x) and cos(x) in a single graph
Make a QR-code of my contact information: Stephan Seeger; Homepage: domain-seeger.de
or after uploading a data set (e.g. from Kaggle)
Explain the dataset.
Show 4 different ways of displaying the data visually.
Before, such functionality was only available via the Notable plugin or via the open-source implementation GPT-Code-UI on GitHub.
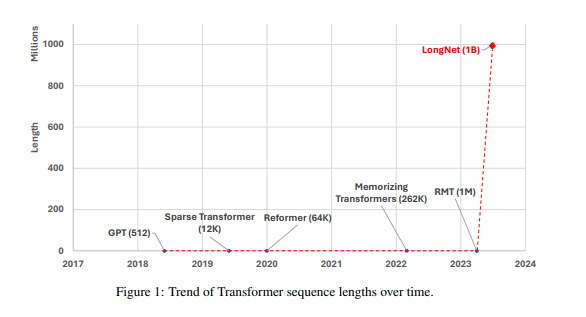
LongNet, a new Transformer variant introduced in recent research by Microsoft, has successfully scaled sequence lengths to over 1 billion tokens without compromising shorter sequence performance. Its key innovation, dilated attention, allows an exponential expansion of the attentive field with growing distance. The model exhibits linear computational complexity and logarithmic token dependency, while also demonstrating strong performance on long-sequence modeling and general language tasks.
On June 13, 2023, OpenAI announced a number of updates to their API:
new function calling capability in the Chat Completions API
new 16k context version of gpt-3.5-turbo with 2 times the price as the standard 4k version ($0.003 per 1K input tokens and $0.004 per 1K output)
75% cost reduction on the embeddings model ($0.0001 per 1K tokens)
25% cost reduction on input tokens for gpt-3.5-turbo ($0.0015 per 1K input tokens and $0.002 per 1K output tokens)
stable model names (gpt-3.5-turbo, gpt-4, and gpt-4-32k) will automatically be upgraded to the new models (gpt-3.5-turbo-0613, gpt-4-0613, and gpt-4-32k-0613) on June 27
deprecation of gpt-3.5-turbo-0301 and gpt-4-0314 models after Sept 13
All models come with the same data privacy and security guarantees introduced on March 1, i.e. requests and API data will not be used for training.
The new function calling capability in gpt-3.5-turbo-0613, and gpt-4-0613, which is achieved by the new API parameters, functions and function_call, in the /v1/chat/completions endpoint allows e.g. the following use cases:
Chatbots that answer questions by calling external tools (like ChatGPT Plugins)
Convert natural language into API calls or database queries