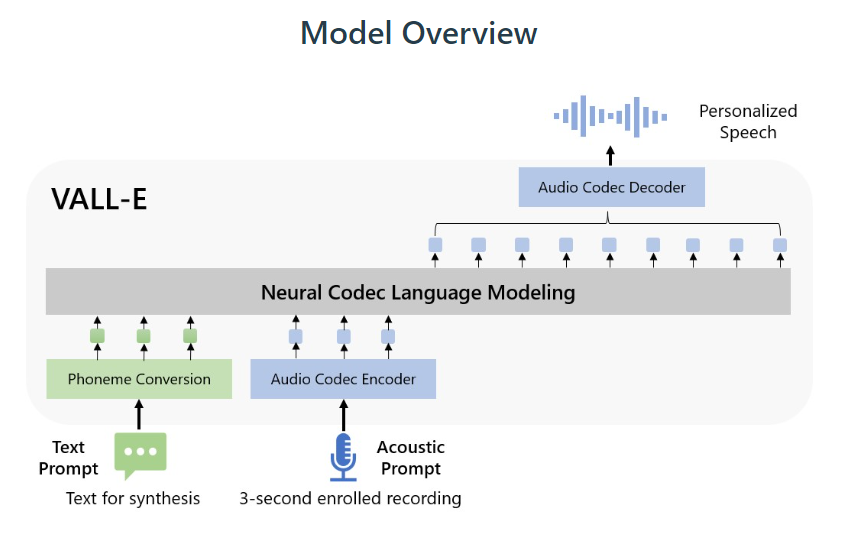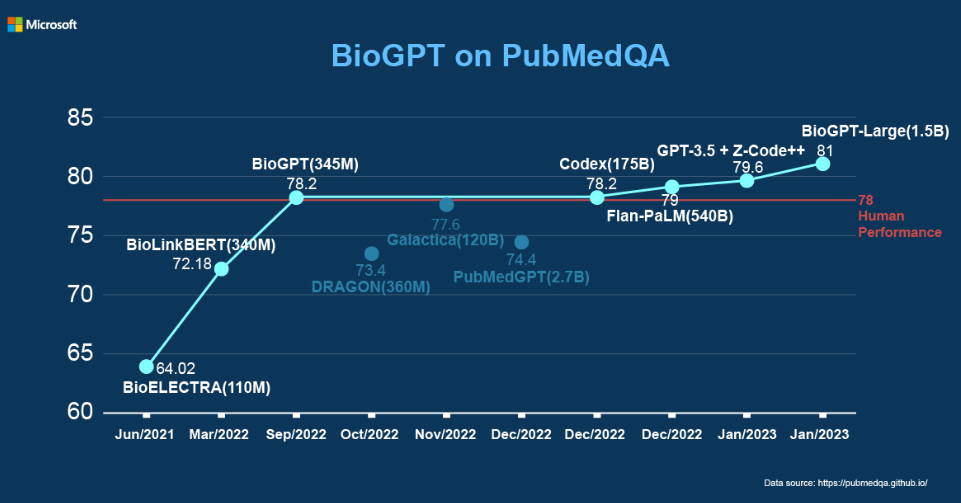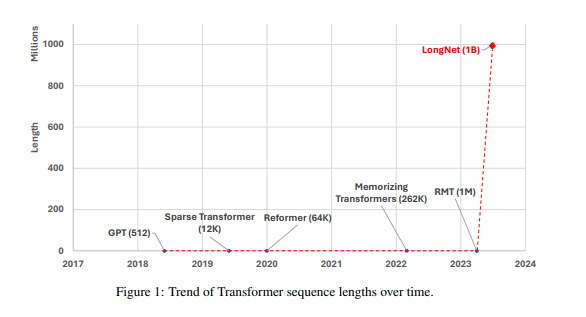
LongNet, a new Transformer variant introduced in recent research by Microsoft, has successfully scaled sequence lengths to over 1 billion tokens without compromising shorter sequence performance. Its key innovation, dilated attention, allows an exponential expansion of the attentive field with growing distance. The model exhibits linear computational complexity and logarithmic token dependency, while also demonstrating strong performance on long-sequence modeling and general language tasks.