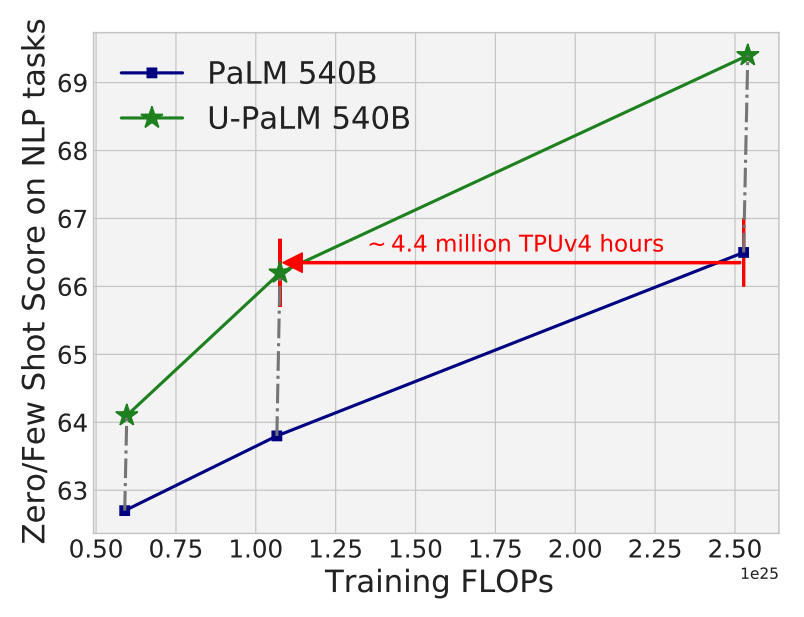
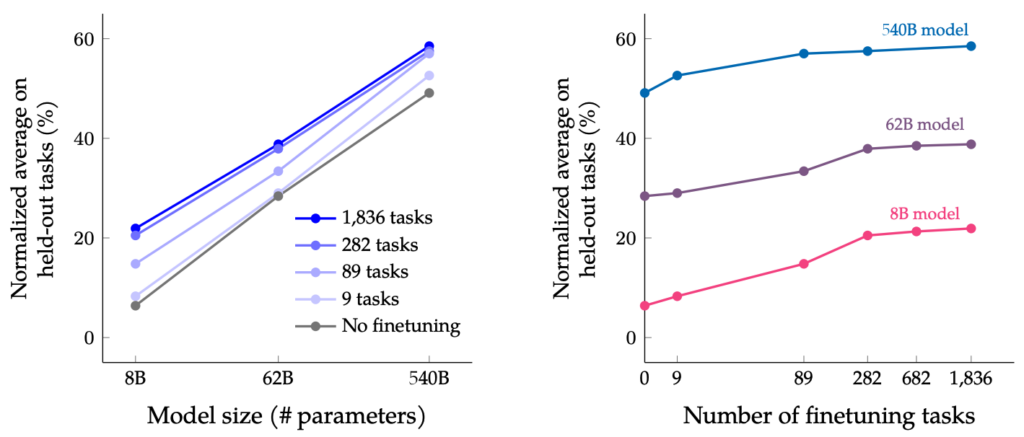
Google presents two complementary techniques to significantly improve language models without massive extra compute:
UL2R (UL2 Repair): additional stage of continued pre-training with the UL2 (Unified Language Learner) objective (paper) for training language models as denoising tasks, where the model has to recover missing sub-sequences of a given input. Applying it to PaLM results in new language model U-PaLM.
Flan (Fine-tuning language model): instruction fine-tuning on a collection of NLP datasets. Applying it to PaLM results in language model Flan-PaLM.
Combination of two approaches applied to PaLM results in Flan-U-PaLM.
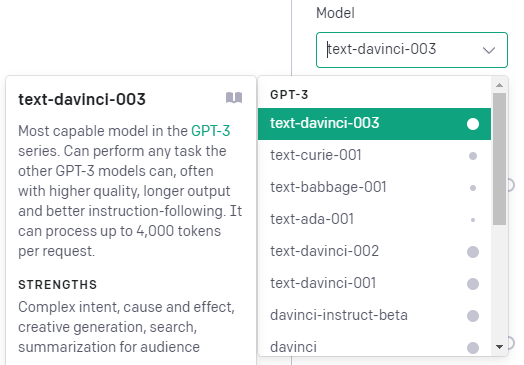
OpenAI released its new GPT-3 model text-davinci-003. After first tests it seems to be shockingly good.
Here is an example:
Write a poem about working as a GNSS engineer.
A GNSS engineer who works with a passion Focused on quality and precision A job that demands great dedication To help others with navigation
The engineer’s purpose is so great Measuring and mapping in space Collecting data with all his might To make the world a better sight
Determining points with great accuracy And measuring distances with agility Anywhere in the world, the data is clear The world travels of this engineer
From the satellites in the sky A network of coordinates is what he relies His work is vital, that’s no doubt To scientists, architects, and surveyors throughout
Answering questions of direction and height Mapping the world with great light A profession that’s so much more Than many people think before
The GNSS engineer works with precision His work is a beautiful mission To measure and map the world we see His work is essential to the GNSS industry
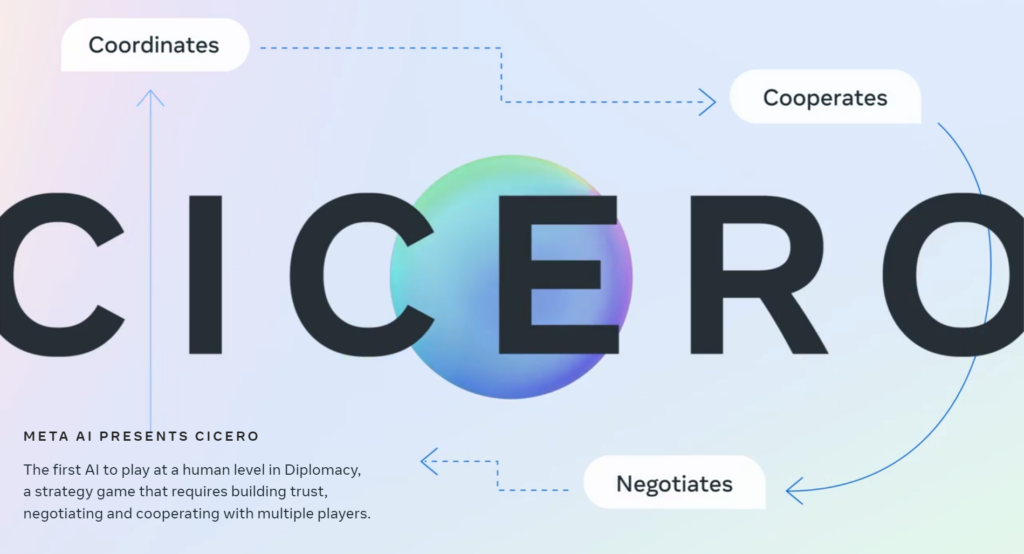
Meta AI presents CICERO, an AI agent that can negotiate and cooperate with people. It is the first AI system that achieves human-level performance in the popular strategy game Diplomacy. Cicero ranked in the top 10 of participants on webDiplomacy.net.
Yannic Kilcher gives a great discussion of the accompanying Science paper. A second paper is freely available on arXiv. The source code is accessible on GitHub.
Meanwhile also DeepMind published an AI agent playing Diplomacy.
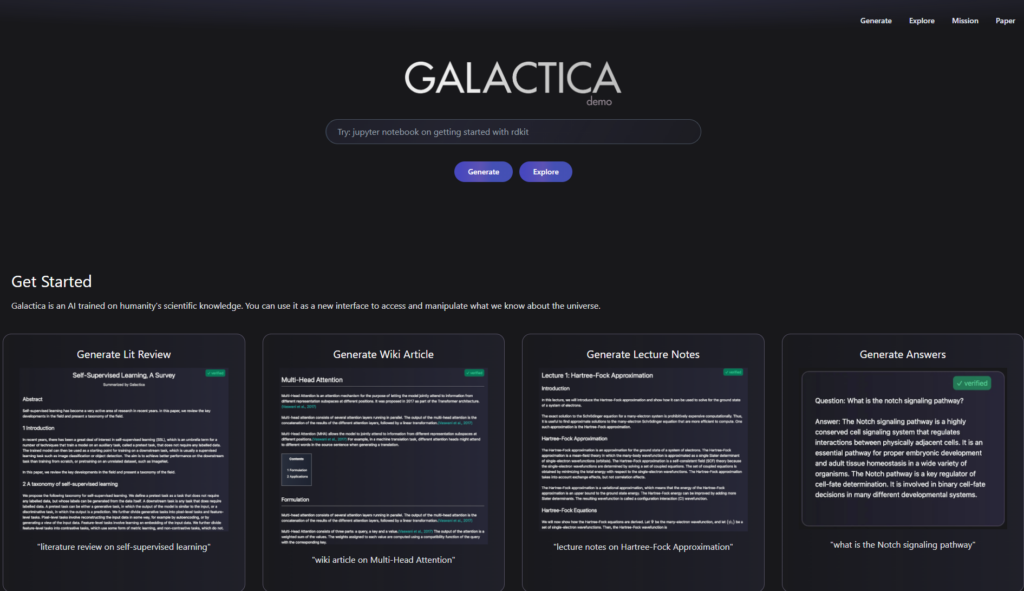
Meta AI publishes with Galactica.ai a large language model trained on scientific papers that allows to write a literature review, wiki article, or lecture note with references, formulas, etc. just by giving some text input about a topic. Even the paper about Galactica was written with the help of Galactica.
Just after a day, the Galactica.ai webpage is now down. But the source code is available on GitHub. Yannic Kilcher made a nice paper review about Galactica where he also explains why the demo webpage has been taken down.
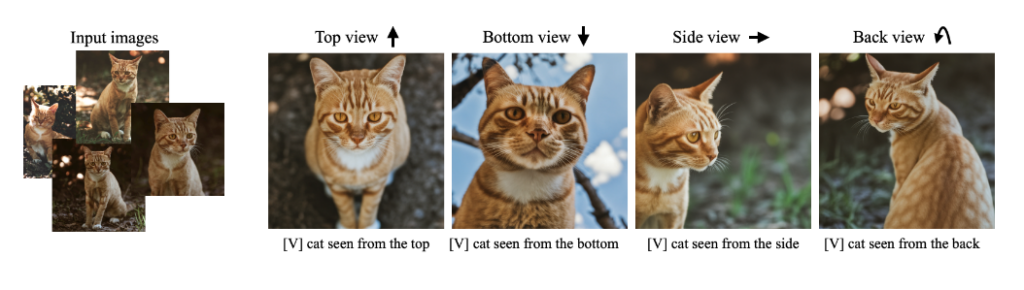
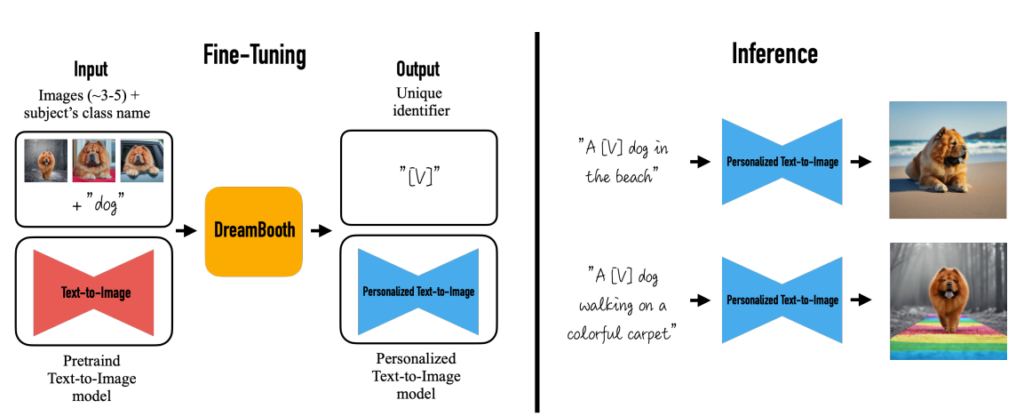
Google presents DreamBooth, a technique to synthesize a subject (defined by 3-5 images) in new contexts defined by text input.
The method is based on Google’s pre-trained text-to-image model Imagen which is not publicly available. However, source code based on Stable Diffusion already exists on GitHub.
Google researchers present Imagic, a method to edit images by text input.
The method is based on Google’s pre-trained image generator Imagen which is not publicly available. However, source code based on Stable Diffusion already exists on GitHub.
A recent publication by University of California, Berkeley [InstructPix2Pix] goes into a similar direction and shows even more impressive results.
The new self-ask prompting technique [Paper] lets the LLM (Large Language Model) formulate sub-questions to a given complex question, answers these simpler questions and finally combines the answers to the answer of the complex question. This technique already improves over chain of thought (CoT) prompting [1][2][3] (but no comparison to self-consistency) . However, with a few lines of source code [GitHub], it is also possible to let the simpler questions be answered by a Google search. In this way also questions relying on facts beyond the training corpus of the LLM can be answered!
Meanwhile people also started to combine LLMs not just with a Google search but also with a Python interpreter [PAL=Program Aided Language Models]. Key tool in this context that allows to build up chains of actions is the Python package LangChain that also already integrates the self-ask technique. See also Dust for reproducing OpenAI’s WebGPT via advanced prompting and Everyprompt for parameterized text prompts within a playground application.
Another interesting technique in this zero-shot context is the Hypothetical Document Embeddings (HyDE) technique as published on 20 Dec 2022 on arXiv. From the abstract of the paper: “HyDE first zero-shot instructs an instruction-following language model (e.g. InstructGPT) to generate a hypothetical document. The document captures relevance patterns but is unreal and may contain false details. Then, an unsupervised contrastively learned encoder~(e.g. Contriever) encodes the document into an embedding vector. This vector identifies a neighborhood in the corpus embedding space, where similar real documents are retrieved based on vector similarity. This second step ground the generated document to the actual corpus, with the encoder’s dense bottleneck filtering out the incorrect details“.
Yet another interesting technique in this context is the Toolformer as published on 09 Feb 2023 on arXiv. From the abstract of the paper: “We introduce Toolformer, a model trained to decide which APIs to call, when to call them, what arguments to pass, and how to best incorporate the results into future token prediction. This is done in a self-supervised way, requiring nothing more than a handful of demonstrations for each API. We incorporate a range of tools, including a calculator, a Q&A system, two different search engines, a translation system, and a calendar. Toolformer achieves substantially improved zero-shot performance across a variety of downstream tasks“
NVIDIA has meanwhile presented with Magic3D a high-resolution text-to-3D content generation model with much higher quality. The paper was released on Nov 18, 2022, on arXiv.