On Dec 6, 2023, Google launched its new multimodal model Gemini that will work across Google products like search, ads, and the chatbot Bard. Gemini was trained jointly across text, image, audio, and video and has a 32K context window.
Gemini 1.0 comes in three different sizes:
Gemini Ultra: largest and most capable model to be released at the beginning of 2024
Gemini Pro: best model that is available immediately within Bard in 170 countries (but not yet in the EU and UK)
Gemini Nano: most efficient model for mobile devices with the same availability as Pro; Nano-1 (1. 8B parameters), Nano-2 (3.25B parameters)
Interestingly, Gemini was trained on a large fleet of TPUv4 accelerators across multiple data centers. At such scales, machine failures due to cosmic rays are commonplace and have to be handled (Gemini report, page 4).
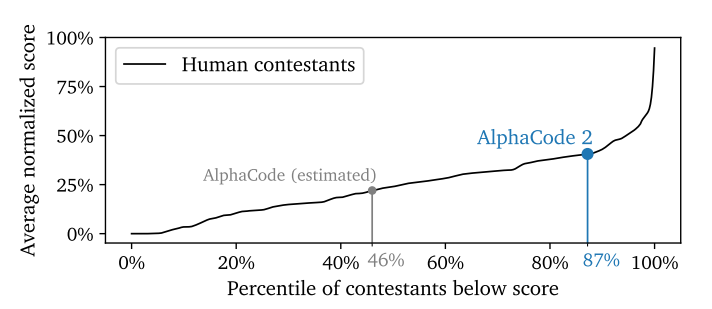
When paired with search and tool-use techniques, Gemini forms the basis for advanced reasoning systems like AlphaCode 2, which excels in competitive programming challenges against human competitors. AlphaCode 2, solely based on Gemini Pro and not yet on Gemini Ultra, shows a substantial improvement over its predecessor by solving 43% of problems on Codeforces, a 1.7x increase. In this way, AlphaCode 2 performs better than 87% of human competitors. However, due to its intensive machine requirements to generate, filter, and score up to a million solutions, AlphaCode 2 is currently not feasible for customer use, although Google is working on this.
After weeks of “less exciting” news in the AI space since the release of Llama 2 by Meta on July 18, 2023, there were a bunch of announcements in the last few days by major players in the AI space:
A vast number of AI experts have signed a statement to raise public awareness regarding the most severe risks associated with advanced AI, aiming to mitigate the risk of human extinction. Among the signatories are Turing Award laureates Geoffrey Hinton and Yoshua Bengio (but not Yann LeCun from Meta), and the CEOs of leading AI companies like Sam Altman from OpenAI, Demis Hassabis from Google DeepMind, Dario Amodei from Anthropic, and Emad Mostaque from Stability AI.
The statement is featured on the webpage of the Center for AI Safety, which provides a list of eight examples of existential risks (x-risks). The enumerated risks are based on the publication “X-Risk Analysis for AI Research” which appeared on Sept. 20, 2022, on arXiv. This highly valuable paper also lists in its Appendix a bunch of practical steps to mitigate risks.
The listed risks are:
Weaponization: Malicious actors could repurpose AI to be highly destructive.
Misinformation: AI-generated misinformation and persuasive content could undermine collective decision-making, radicalize individuals, or derail moral progress.
Proxy Gaming: AI systems may pursue their goals at the expense of individual and societal values.
Enfeeblement: Humanity loses the ability to self-govern by increasingly delegating tasks to machines.
Value Lock-in: Highly competent systems could give small groups of people a tremendous amount of power, leading to a lock-in of oppressive systems.
Emergent Goals: The sudden emergence of capabilities or goals could increase the risk that people lose control over advanced AI systems.
Deception: To better understand AI systems, we may ask AI for accurate reports about them. However, since deception may help agents to better achieve their goals and this behavior may have strategic advantages, it is never safe to trust these systems.
Power-Seeking Behavior: Companies and governments have strong economic incentives to create agents that can accomplish a broad set of goals. Such agents have instrumental incentives to acquire power, potentially making them harder to control.
This statement about AI risks appeared a few days after an OpenAI blog post by Sam Altman, Greg Brockman, and Ilya Sutskever, which also addresses the mitigation of risks associated with AGI or even superintelligence that could arise within the next 10 years.
Google Quantum AI has made a groundbreaking observation of non-Abelian anyons, particles that can exhibit any intermediate statistics between the well-known fermions and bosons. This breakthrough has the potential to transform quantum computing by significantly enhancing its resistance to noise. The term “anyon” was coined by Nobel laureate physicist Frank Wilczek in the early 1980s while studying Abelian anyons. He combined “any” with the particle suffix “-on” to emphasize the range of statistics these particles can exhibit.
Fermions are elementary particles with half-integer spin, such as quarks and leptons (electrons, muons, tauons, as well as their corresponding neutrinos), and their wave functions are anti-symmetrical under the exchange of identical particles. Examples of bosons, which have integer spin and symmetrical wave functions under particle exchange, include the Higgs boson and the gauge bosons: photons, W- and Z bosons, and gluons. In contrast, anyons obey fractional quantum statistics and possess more exotic properties that can just exist in two-dimensional systems.
The history of anyons dates back to Nobel laureate Robert Laughlin’s study of the fractional quantum Hall effect, a phenomenon observed in two-dimensional electron systems subjected to strong magnetic fields. In 1983, he proposed a wave function to describe the ground state of these systems, which led to the understanding that the fractional quantum Hall effect involves quasiparticles with fractional charge and statistics. These quasiparticles can be considered as anyons in two-dimensional space.
Anyons can be categorized into two types: Abelian and non-Abelian. Abelian anyons obey Abelian (commutative) statistics, which were studied by Wilczek and Laughlin. Under particle exchange, they pick up a phase factor of e^i*theta, where theta is a scalar that is not just 0 as for bosons or pi as for fermions. Non-Abelian anyons, on the other hand, have more exotic properties: when exchanged, their quantum states change in a non-trivial way that depends on the order of the exchange, leading to a “memory” effect. Under particle exchange, their wavefunction picks up a phase factor of U=e^i*A with Hermitian matrix A that depends on the exchanged particles. As unitary matrices usually do not commute, it is this more-dimensional phase factor that explains the non-commutativity of non-Abelian anyons. This memory effect makes non-Abelian anyons particularly interesting for topological quantum computation. While the theoretical concept of non-Abelian anyons was already discussed around 1991, it was Alexei Kitaev who made the connection to fault-tolerant, topological quantum computing in a 1997 paper.
Microsoft, among other companies, has been working on harnessing non-Abelian anyons for topological quantum computing, focusing on a specific class called Majorana zero modes, which can be realized in hybrid semiconductor-superconductor systems. “Zero modes” in quantum mechanics refer to states that exist at the lowest energy level of a quantum system, also known as the ground state. Majorana fermions are a type of fermion that were first predicted by the Italian physicist Ettore Majorana in 1937. Their defining property is that they are their own antiparticles. This is unusual for fermions, which typically have distinct particles and antiparticles due to their charge (in contrast to a boson like the photon). While Majorana zero-modes have not been observed as elementary particles, they have found a home in the realm of condensed matter physics, specifically within certain “topological” materials. Here, they manifest as emergent collective behaviors of electrons, known as quasiparticles.
These quasiparticles, termed topological Majorana fermions, appear in the atomic structure of these materials. Intriguingly, they’re found in excited states, seemingly at odds with the “zero-mode” terminology which implies a ground state. The apparent contradiction can be resolved by understanding that Majorana zero modes are ground states within their own subsystem, the specific excitation they form. However, their presence indicates an excited state for the overall electron system, compared to a state with no Majorana zero modes. In other words, they are a ground state property of an excited electron system.
In a recent paper published in Nature on May 11, 2023, Google Quantum AI reported their first-ever observation of non-Abelian anyons using a superconducting quantum processor (see also article on arXiv from 19 Oct 2022). They demonstrated the potential use of these anyons in quantum computations, such as creating a Greenberger-Horne-Zeilinger (GHZ) entangled state by braiding non-Abelian anyons together.
This achievement complements another recent study publishedon May 9, 2023, by quantum computing company Quantinuum, which demonstrated non-Abelian braiding using a trapped-ion quantum processor. The Google team’s work shows that non-Abelian anyon physics can be realized on superconducting processors, aligning with Microsoft’s approach to quantum computing. This breakthrough has the potential to accelerate progress towards fault-tolerant topological quantum computing.
Google revealed at Google I/O on May 10, 2023, PaLM 2 (API, paper), its latest AI language model that powers 25 Google products, including Search, Gmail, Docs, Assistant, Translate, and Photos.
PaLM 2 has 4 models that differ in size: Gecko, Otter, Bison, and Unicorn. Gecko is so lightweight that it can work on mobile devices.
PaLM 2 can be finetuned on domain-specific knowledge (Sec-PaLM with security knowledge, Med-PaLM 2 with medical knowledge)
Bard now works with PaLM 2; with extensions, Bard can call tools like Sheets, Colab for coding, Lenses, Maps, Adobe Firefly to create images, etc.; Bard is multimodal and can understand images
PaLM 2 is also powering Duet AI for Google Cloud, a generative AI collaborator designed to help users learn, build and operate faster
PaLM 2 is released in 180+ regions and countries, however, e.g. not yet in Canada, and in the EU
Google also announced the availability of MusicLM, a text-to-music generative model.
OpenAI reacted to this announcement on May 12 by announcing that Browsing & Plugins are rolled out over the subsequent week for all Plus users. As of May 17, I can confirm that both features are now operational for me.
1st-level generative AI as applications that are directly based on X-to-Y models (foundation models that build a kind of operating system for downstream tasks) where X and Y can be text/code, image, segmented image, thermal image, speech/sound/music/song, avatar, depth, 3D, video, 4D (3D video, NeRF), IMU (Inertial Measurement Unit), amino acid sequences (AAS), 3D-protein structure, sentiment, emotions, gestures, etc., e.g.
X = 3D-protein, Y = AAS: ProteinMPNN (from Baker Lab)
X = 3D structure, Y = AAS: RFdiffusion (from Baker Lab)
and 2nd-level generative AI that builds some kind of middleware and allows to implement agents by simplifying the combination of LLM-based 1st-level generative AI with other tools via actions (like web search, semantic search [based on embeddings and vector databases like Pinecone, Chroma, Milvus, Faiss], source code generation [REPL], calls to math tools like Wolfram Alpha, etc.), by using special prompting techniques (like templates, Chain-of-Thought [COT], Self-Consistency, Self-Ask, Tree Of Thoughts, ReAct [Reason + Act], Graph of Thoughts) within action chains, e.g.
we currently (April/May/June 2023) see a 3rd-level of generative AI that implements agents that can solve complex tasks by the interaction of different LLMs in complex chains, e.g.
However, older publications like Cicero may also fall into this category of complex applications. Typically, these agent implementations are (currently) not built on top of the 2nd-level generative AI frameworks. But this is going to change.
Other, simpler applications that just allow semantic search over private documents with a locally hosted LLM and embedding generation, such as e.g. PrivateGPT which is based on LangChain and Llama (functionality similar to OpenAI’s ChatGPT-Retrieval plugin), may also be of interest in this context. And also applications that concentrate on the code generation ability of LLMs like GPT-Code-UI and OpenInterpreter, both open-source implementations of OpenAI’s ChatGPT Code Interpreter/AdvancedDataAnalysis (similar to Bard’s implicit code execution; an alternative to Code Interpreter is plugin Noteable), or smol-ai developer (that generates the complete source code from a markup description) should be noticed. There is a nice overview of LLM Powered Autonomous Agents on GitHub.
The next level may then be governed by embodied LLMs and agents (like PaLM-E with E for Embodied).
The Future of Life Institute initiated an open letter in which they call on all AI labs to immediately pause for at least 6 months the training of AI systems more powerful than GPT-4 [notice that OpenAI already trains GPT-5 for some time]. They state that powerful AI systems should be developed only once we are confident that their effects will be positive and their risks will be manageable.
The gained time should be used to develop safety protocols by AI experts to make the systems more accurate, safe, interpretable, transparent, robust, aligned, trustworthy, and loyal. In addition, they ask for the development of robust AI governance systems by policymakers and AI developers. They also demand well-resourced institutions for coping with the dramatic economic and political disruptions (especially to democracy) that AI will cause.
Notice that the letter is not against further AI development but just to slow down and give society a chance to adapt.
The letter was signed by several influential people, e.g. Elon Musk (CEO of SpaceX, Tesla & Twitter), Emad Mostaque (CEO of Stability AI), Yuval Noah Harari (Author), Max Tegmark (president of Future of Life Institute), Yoshua Bengio (Mila, Turing Prize winner), Stuart Russell (Berkeley).
However, it should be noticed that even more influential people in the AI scene have not (yet) signed this letter, none from OpenAI, Google/Deep Mind, or Meta.
This is not the first time the Future of Live Institute has taken action on AI development. In 2015, they presented an open letter signed by over 1000 robotics and AI researchers urging the United Nations to impose a ban on the development of weaponized AI.
The Future of Life Institute is a non-profit organization that aims to mitigate existential risks facing humanity, including those posed by AI.
Yann LeCun answered on Twitter with a nice fictitious anecdote to the request: The year is 1440 and the Catholic Church has called for a 6 months moratorium on the use of the printing press and the movable type. Imagine what could happen if commoners get access to books! They could read the Bible for themselves and society would be destroyed.
On the same day as OpenAI released GPT-4 (March 14, 2023), Google also announced the availability of the PaLM API for developers on Google Cloud [video]. They said that they are now providing access to foundation models on Google Cloud’s Vertex AI platform, initially for generating text and images, and over time also for audio and video. In addition, with the Generative AI App Builder, they introduced the possibility of quickly building AI-powered chat interfaces and digital assistants.
Finally, Google also made for a limited set of trusted test users generative AI features available within Google Workspace (Gmail and Google Docs).
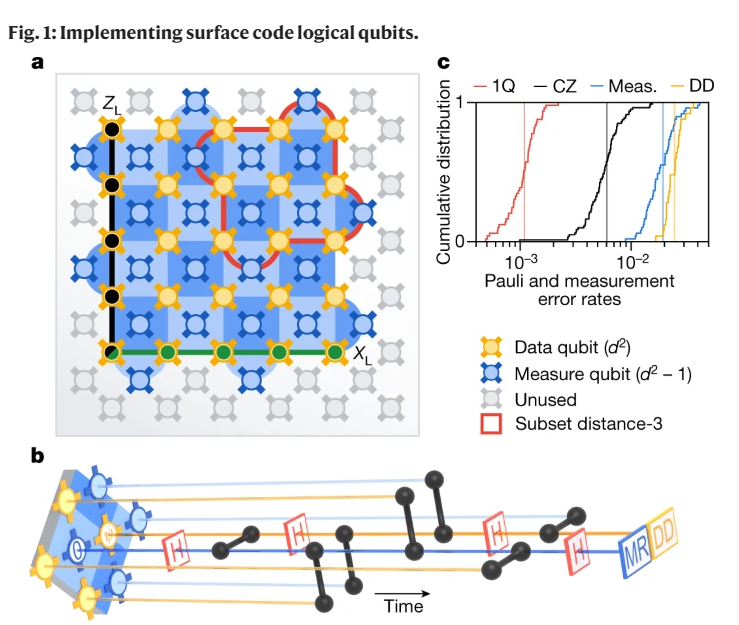
In an announcement from Feb 22, 2023, and in a corresponding Nature paper, Google demonstrates for the first time that logical qubits can actually reduce the error rates in a quantum computer.
Physical qubits have a 1-to-1 relation between a qubit in a quantum algorithm and its physical realization in a quantum system. The problem with physical qubits is that due to thermal noise, they can decohere so they no longer build such a quantum system with a superposition of the bit states 0 and 1. How often this decoherence happens is formalized by the quantum error rate. This error rate influences a quantum algorithm in two ways. First, the more qubits are involved in a quantum algorithm, the higher the probability of an error. Second, the longer a qubit is used in a quantum algorithm and the more gates act on it, i.e. the deeper the algorithm is, also the higher the probability of an error.
It is surprising that it is possible to correct (via quantum error correction algorithms) physical qubit errors without actually measuring the qubits (which would always destroy them). Such error correction codes are at least already known since 1996. The information of a physical qubit that is distributed over a bunch of physical qubits in a way so that certain quantum errors are automatically corrected, builds a logical qubit. However, the physical qubits involved in the logical qubit are also subjected to the quantum error rate. Thus there is an obvious trade-off between involving more physical qubits for a longer time, which could increase the error rate, and having a mechanism to reduce the error rate. Which effect prevails depends on the used error correction code as well as on the error rate of the used physical qubits. Google has now demonstrated for the first time that in their system there is actually an advantage of using a so-called surface code logical qubit.
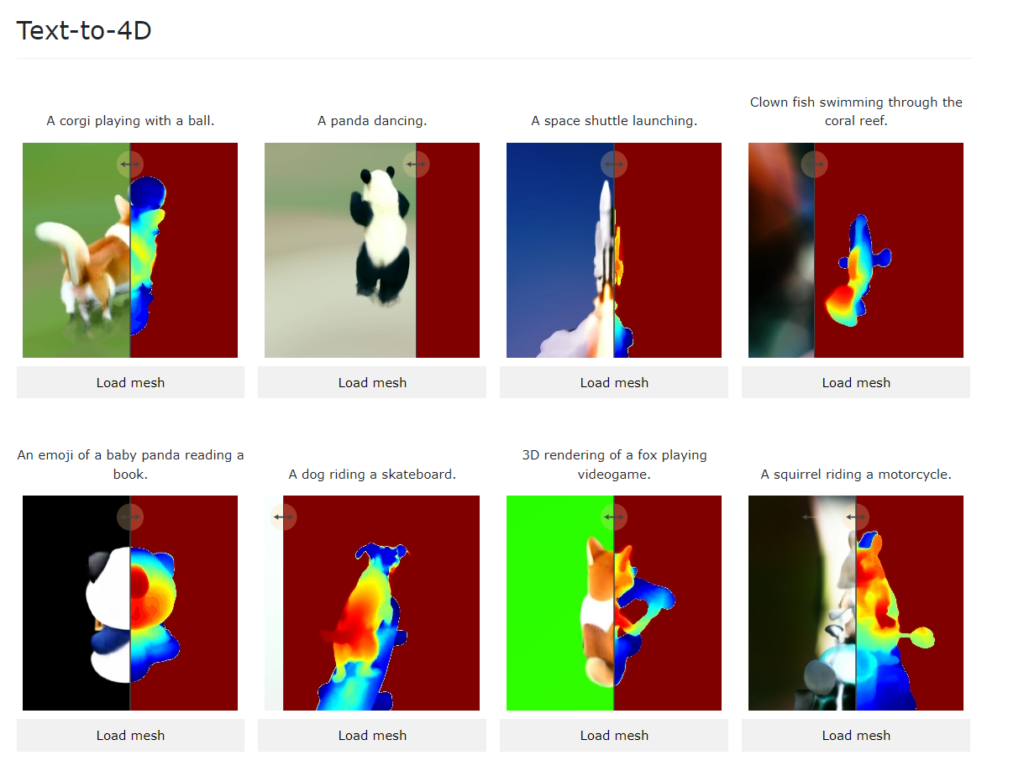
Meta presented with MAV3D (Make-A-Video-3D) a method for generating 4D content, i.e. a 3D video, from a text description by using a 4D dynamic Neural Radiance Field (NeRF) [project page, paper]. Unfortunately, the source code has not been released.