OpenAI rolled out on its DevDay an array of transformative updates and features [blog post, keynote recording]. Here’s a succinct rundown:
Recap: ChatGPT release Nov 30, 2022 with GPT-3.5. GPT-4 release in March 2023. Voice input/output, vision input with GPT-4V, text-to-image with DALL-E 3, ChatGPT Enterprise with enterprise security, higher speed access, and longer context windows. 2M developers, 92% of Fortune 500 companies building products on top of GPT, 100M weekly active users.
New GPT-4 Turbo: OpenAI’s most advanced AI model, 128K context window, knowledge up to April 2023. Reduced pricing: $0.01/1K input tokens (3x cheaper), $0.03/1K output tokens (2x cheaper). Improved function calling (multiple functions in single message, always return valid functions with JSON mode, improved accuracy on returning right function parameters). More deterministic model output via reproducible outputs beta. Access via gpt-4-1106-preview, stable release pending.
GPT-3.5 Turbo Update: Enhanced gpt-3.5-turbo-1106 model with 16K default context. Lower pricing: $0.001/1K input, $0.002/1K output. Fine-tuning available, reduced token prices for fine-tuned usage (input token prices 75% cheaper to $0.003/1K, output token prices 62% cheaper to $0.006/1K). Improved function calling, reproducible outputs feature.
Assistants API: Beta release for creating AI agents in applications. Supports natural language processing, coding, planning, and more. Enables persistent Threads, includes Code Interpreter, Retrieval, Function Calling tools. Playground integration for no-code testing.
Multimodal Capabilities: GPT-4 Turbo supports visual inputs in Chat Completions API via gpt-4-vision-preview. Integration with DALL·E 3 for image generation via Image generation API. Text-to-speech (TTS) model with six voices introduced.
Customizable GPTs in ChatGPT: New feature called GPTs allowing integration of instructions, data, and capabilities. Enables calling developer-defined actions, control over user experience, streamlined plugin to action conversion. Documentation provided for developers.
After weeks of “less exciting” news in the AI space since the release of Llama 2 by Meta on July 18, 2023, there were a bunch of announcements in the last few days by major players in the AI space:
1st-level generative AI as applications that are directly based on X-to-Y models (foundation models that build a kind of operating system for downstream tasks) where X and Y can be text/code, image, segmented image, thermal image, speech/sound/music/song, avatar, depth, 3D, video, 4D (3D video, NeRF), IMU (Inertial Measurement Unit), amino acid sequences (AAS), 3D-protein structure, sentiment, emotions, gestures, etc., e.g.
X = 3D-protein, Y = AAS: ProteinMPNN (from Baker Lab)
X = 3D structure, Y = AAS: RFdiffusion (from Baker Lab)
and 2nd-level generative AI that builds some kind of middleware and allows to implement agents by simplifying the combination of LLM-based 1st-level generative AI with other tools via actions (like web search, semantic search [based on embeddings and vector databases like Pinecone, Chroma, Milvus, Faiss], source code generation [REPL], calls to math tools like Wolfram Alpha, etc.), by using special prompting techniques (like templates, Chain-of-Thought [COT], Self-Consistency, Self-Ask, Tree Of Thoughts, ReAct [Reason + Act], Graph of Thoughts) within action chains, e.g.
we currently (April/May/June 2023) see a 3rd-level of generative AI that implements agents that can solve complex tasks by the interaction of different LLMs in complex chains, e.g.
However, older publications like Cicero may also fall into this category of complex applications. Typically, these agent implementations are (currently) not built on top of the 2nd-level generative AI frameworks. But this is going to change.
Other, simpler applications that just allow semantic search over private documents with a locally hosted LLM and embedding generation, such as e.g. PrivateGPT which is based on LangChain and Llama (functionality similar to OpenAI’s ChatGPT-Retrieval plugin), may also be of interest in this context. And also applications that concentrate on the code generation ability of LLMs like GPT-Code-UI and OpenInterpreter, both open-source implementations of OpenAI’s ChatGPT Code Interpreter/AdvancedDataAnalysis (similar to Bard’s implicit code execution; an alternative to Code Interpreter is plugin Noteable), or smol-ai developer (that generates the complete source code from a markup description) should be noticed. There is a nice overview of LLM Powered Autonomous Agents on GitHub.
The next level may then be governed by embodied LLMs and agents (like PaLM-E with E for Embodied).
On the same day as OpenAI released GPT-4 (March 14, 2023), Google also announced the availability of the PaLM API for developers on Google Cloud [video]. They said that they are now providing access to foundation models on Google Cloud’s Vertex AI platform, initially for generating text and images, and over time also for audio and video. In addition, with the Generative AI App Builder, they introduced the possibility of quickly building AI-powered chat interfaces and digital assistants.
Finally, Google also made for a limited set of trusted test users generative AI features available within Google Workspace (Gmail and Google Docs).
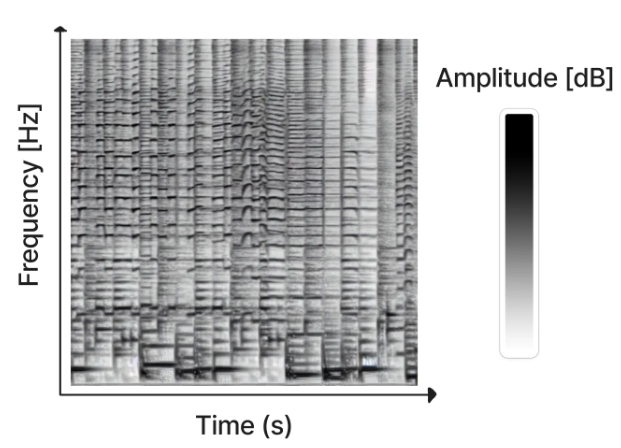
By using the stable diffusion model v1.5 without any modifications, just fine-tuned on images of spectrograms paired with text, the software RIFFUSION (RIFF + diffusion) generates incredibly interesting music from text input. By interpolating in latent space it is possible to transition from one text prompt to the next. You can try out the model here.
The authors provide source code on GitHub for an interactive web app and an inference server. A model checkpoint is available on Hugging Face.
There is a nice video about RIFFUSION by Alan Thompson on youtube.
Even more shocking than using diffusion on spectrograms and getting great results may be a paper by Google Research published on Dec 15, 2022. They use text as an image and train their model with contrastive loss alone, thus calling their model CLIP-Pixels Only (CLIPPO). It’s a joint model for processing images and text with a single ViT (Vison Transformer) approach and astonishing performance.
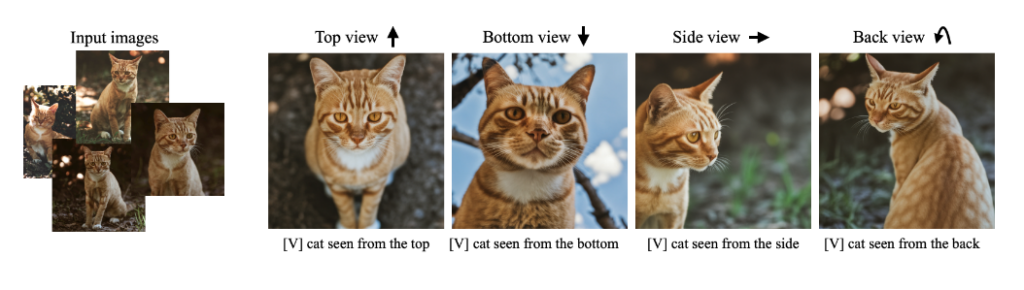
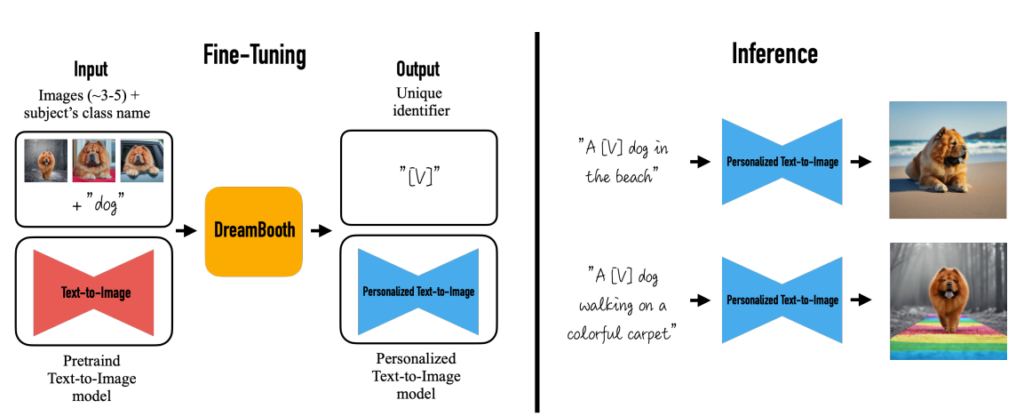
Google presents DreamBooth, a technique to synthesize a subject (defined by 3-5 images) in new contexts defined by text input.
The method is based on Google’s pre-trained text-to-image model Imagen which is not publicly available. However, source code based on Stable Diffusion already exists on GitHub.
Google researchers present Imagic, a method to edit images by text input.
The method is based on Google’s pre-trained image generator Imagen which is not publicly available. However, source code based on Stable Diffusion already exists on GitHub.
A recent publication by University of California, Berkeley [InstructPix2Pix] goes into a similar direction and shows even more impressive results.