In a recent study by the University of Montana, GPT-4 demonstrated remarkable performance in the Torrance Tests of Creative Thinking (TTCT, a standard test for measuring creativity), matching the top 1% of human thinkers. The model excelled in fluency and originality. These findings imply that the creative abilities of GPT-4 could potentially surpass those of humans.
For a recent benchmark on advanced reasoning capabilities of large language models take a look at the ARB (Advanced Reasoning Benchmark).
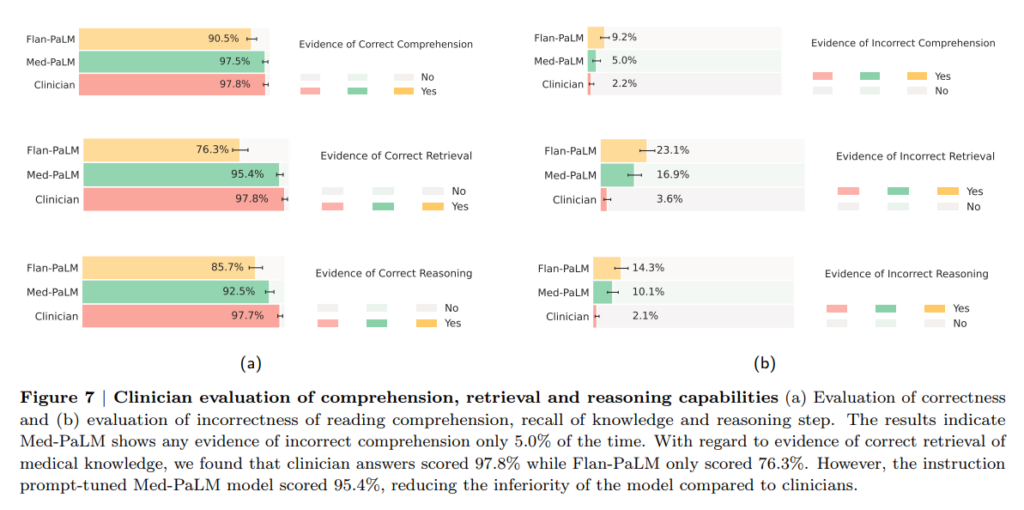
In a recent paper from Dec 26, 2022, Google demonstrates that its large language model Med-PaLM, based on 540 billion parameters with a special instruction prompt tuning for the medical domain, reaches almost clinician’s performance on new medical benchmarks MultiMedQA (benchmark combining six existing open question answering datasets spanning professional medical exams, research, and consumer queries) and HealthSearchQA (a new free-response dataset of medical questions searched online). The evaluation of the answers considering factuality, precision, possible harm, and bias was done by human experts.
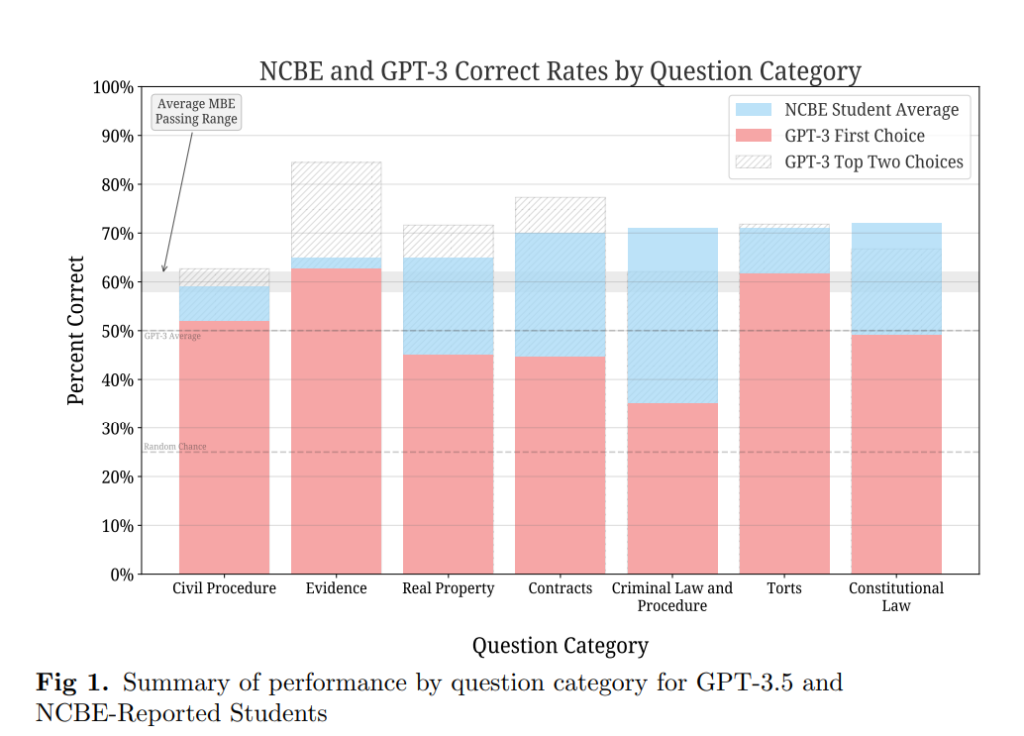
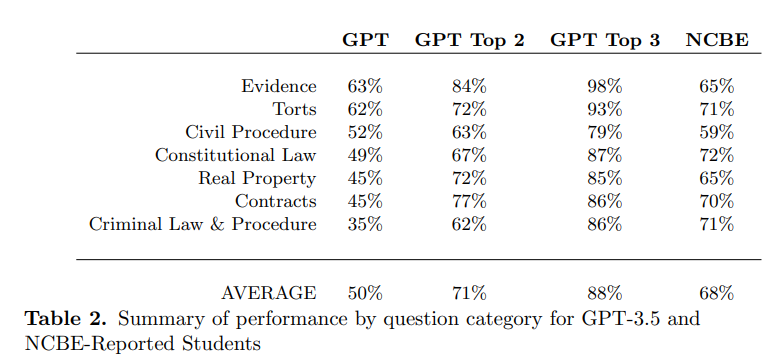
In the United States, most jurisdictions require applicants to pass the Bar Exam in order to practice law. This exam typically requires several years of education and preparation (seven years of post-secondary education, including three years at an accredited law school).
In a publication from Dec 29, 2022, the authors evaluated the performance of GPT-3.5 on the multiple choice part of the exam. While GPT is not yet passing that part of the exam, it significantly exceeded the baseline random chance rate of 25% and reached the average human passing rate for the categories Evidence and Torts. On average, GPT is performing about 17% worse than human test-takers across all categories.
Similar to this publication is the report that ChatGPT was able to pass the Wharton Master of Business Applications (MBA) exam.
On March 15, 2023, a paper was published that stated that GPT-4 significantly outperforms both human test-takers and prior models, demonstrating a 26% increase over GPT-3.5 and beating humans in five of seven subject areas.
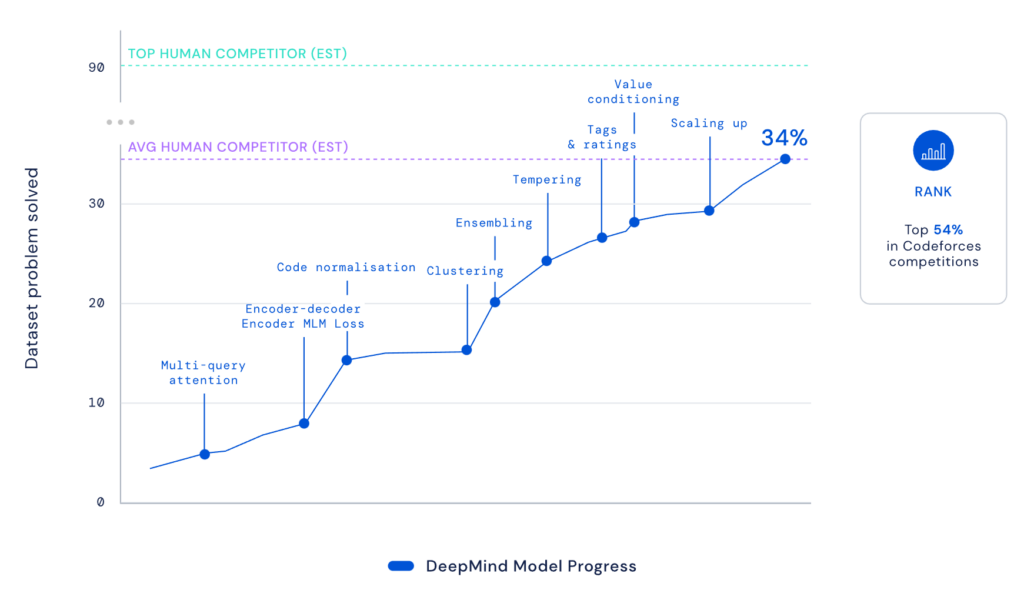
DeepMind publishes that AlphaCode reaches median human competitor performance in real-world programming competitions on Codeforces by now scaling up the number of possible solutions to the problem to millions instead of tens like before.
This announcement was originally made on 02 Feb 2022 and was now published on 08 Dec 2022 in Science.