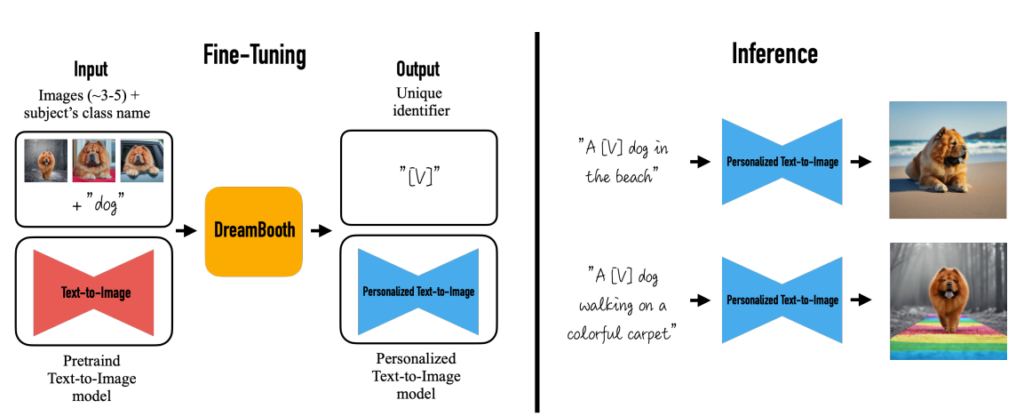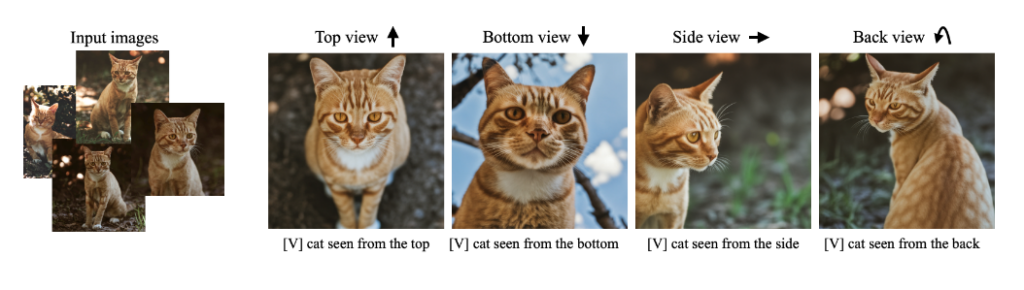


Google presents DreamBooth, a technique to synthesize a subject (defined by 3-5 images) in new contexts defined by text input.
The method is based on Google’s pre-trained text-to-image model Imagen which is not publicly available. However, source code based on Stable Diffusion already exists on GitHub.